TL;DR
- AI search has five working parts: training, grounding/RAG, query fan-out, citations, and personalisation. Optimising for AI search means understanding what each part does — not “doing SEO better”
- The strongest correlation with AI Overview brand mentions in Ahrefs’ study of ~75,000 brands was branded web mentions (0.664) — more than double the correlation for DR (0.326) or backlinks (0.218). YouTube mentions correlate even more strongly: 0.74 with AI mentions
- Only ~12% of AI-cited links rank for the user’s original prompt — because LLMs don’t search the prompt; they decompose it into multiple sub-queries (query fan-out)
- AI engines retrieve snippets, not pages. Cited URLs show stronger semantic similarity with the fan-out query (0.656 title correlation), and the average age of AI-cited URLs is 1,064 days vs 1,432 days in organic SERPs — about 25.7% fresher
- 43.8% of source links in Ahrefs’ study of 750 top-of-funnel prompts (e.g. “best web design agencies in London”) were listicles. And the average word count of pages cited in AI Overviews is 1,282 words — the middle band (350–2,000 words) accounts for ~67% of citations, while pages over 2,000 words are only 16.0%. Density beats length
- Brand Radar (Ahrefs’ AI-visibility tracker) indexes 353 million prompts across ChatGPT, AI Mode, AI Overviews, Copilot, Gemini, and Grok — built specifically because personalisation makes single-instance “is my brand showing up?” checks unreliable
About the Session
Talk title: How AI Search Engines Really Work
Track: Understanding AI Behaviour
Date: Friday 1 May 2026, 14:00
Venue: Syndicate 1&2 — Anything is Possible stage, Brighton Centre, Kings Road, Brighton and Hove, BN1 2GR, United Kingdom
About the Speaker
Ryan Law — Director of Content Marketing, Ahrefs
Ryan leads content marketing at Ahrefs and is one of the most-cited writers and analysts in the SEO industry. Previously CMO at content marketing agency Animalz; agency co-founder. Across his career he has worked with companies including Google, GoDaddy, and Zapier. His talk in the “Understanding AI Behaviour” track on Day 2, alongside Veronika Ulla Höller (Tresorit) and Philip Armstrong (Semrush), was one of the most rigorously research-backed sessions of the entire conference.
The Setup: “What Actually Happens When ChatGPT or AI Mode Recommends a Product?”
Ryan opened by admitting the question that brought him to the stage: as a content marketer, he really wants to get cited in ChatGPT. (*panicked breathing sounds*.) That requires understanding what’s actually happening inside these systems. So he came to BrightonSEO with the research and the framework.
His framing for the future of search: ask follow-up questions, get personalised responses, zero-click answers, interactivity and agency. That’s where everything is heading.
The Five Working Parts of AI Search
Ryan’s working model — the spine of the talk:
- Training — “learning” about your brand
- Grounding — using traditional search indexes
- Query fan-out — generating search queries to find information
- Citations — selecting which URLs to cite
- Personalisation — tailoring answers to individual users
Each part has its own optimisation logic. Most “AI SEO” advice circulating online conflates these layers. Ryan’s framework lets you triage advice by which layer the tactic actually affects.

Part 1: Training
LLMs are trained on enormous corpora: Common Crawl, proprietary crawls, licensed web data, Google Books, Project Gutenberg, BookCorpus, Wikipedia, GitHub repos, arXiv, PubMed/PMC, S2ORC, Reddit (Pushshift), Stack Exchange, USPTO patents, FreeLaw, OpenSubtitles, Europarl. These flow through intermediate datasets (C4, RefinedWeb, OSCAR, The Stack, WebText, The Pile, Dolma, ROOTS) into both open and closed model outputs. Not every model uses Common Crawl — proprietary crawls and licensed data feed the closed models.
The way your brand appears across that corpus shapes what the model “knows” about you. Ryan quoted Gianluca Fiorelli: LLMs learn the relationships between your brand and concepts like “gym” or “noise-cancellation.” These semantic associations directly influence whether and how you’re mentioned.
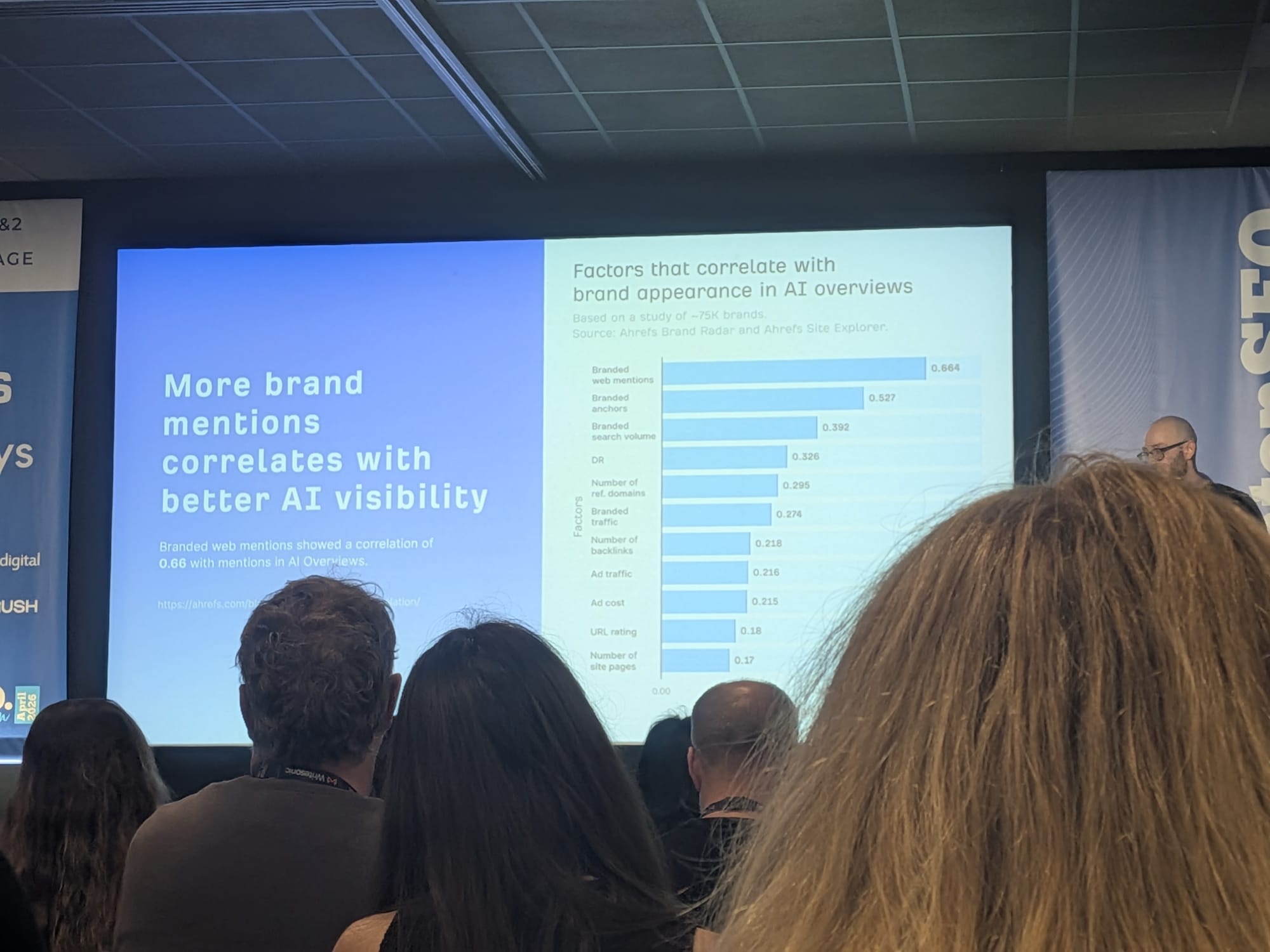
The data, ranked by correlation coefficient — Ahrefs’ study of ~75,000 brands:
| Factor | Correlation with brand appearance in AI Overviews |
|---|---|
| Branded web mentions | 0.664 |
| Branded anchors | 0.527 |
| Branded search volume | 0.392 |
| DR (Domain Rating) | 0.326 |
| Number of referring domains | 0.295 |
| Branded traffic | 0.274 |
| Number of backlinks | 0.218 |
| Ad traffic | 0.216 |
| Ad cost | 0.215 |
| URL rating | 0.18 |
| Number of site pages | 0.17 |
Branded web mentions came out on top at 0.664 — a very large effect by SEO research standards. Notice what is not at the top: DR (0.326), number of backlinks (0.218), URL rating (0.18). The classic “domain authority” signals correlate with AI Overview presence, but at less than half the strength of off-domain brand mentions. (Source: Ahrefs research.)
YouTube mentions showed an even higher correlation: 0.74 with AI mentions. Of all the open-web surfaces where your brand could be mentioned, YouTube is doing disproportionate work for AI visibility (Ahrefs research).
Takeaway #1: get your brand mentioned in lots of relevant places on the internet. The unglamorous answer, but the highest-leverage one.
Part 2: Grounding and RAG
LLMs alone make bad search engines. They’re probabilistic, give no attribution, are prone to hallucination, and have a knowledge cut-off. To work around this, AI search engines wrap LLMs in grounding and Retrieval-Augmented Generation (RAG).
Ryan borrowed Britney Muller’s definition: Grounding comes from ground truth, rooted in statistics and originally cartography, where it literally meant going outside to verify that your map matched reality. When an LLM grounds its outputs, it’s anchoring generation in retrieved real-world context so the answer isn’t hallucinated nonsense.
The decision the LLM makes on every prompt: “Do I need more information to answer this query?”
Three signals that trigger grounding:
- Outside training scope — e.g. “How is Ahrefs’ DR metric calculated?”
- Requires fresh information — e.g. “When was Google’s most recent core update?”
- Requests attribution — e.g. “Provide sources confirming that Google uses clicks in re-ranking”
And critically: AI search engines use different search indexes. ChatGPT uses Bing. Perplexity uses Brave. Gemini uses Google. AI Overviews use Google.
Takeaway #2: ranking highly in traditional search will improve your visibility in AI search. Because the higher you rank in the search index that’s used for grounding, the more likely you are to be retrieved during the grounding step. This kills the “AI vs traditional SEO” framing. They’re not separate disciplines — they’re a stack.
One data point Ryan flagged here: only 12% of cited links rank for the original user prompt (Ahrefs research). Most of the URLs LLMs cite are not the URLs that rank for the user’s actual query. Which leads into the next part…
Part 3: Query Fan-Out

Prompts usually make bad search queries. So LLMs decompose them.
Ryan quoted Mark Williams-Cook: Fan-out queries are generated by the large language model and are therefore non-deterministic: they may change regularly, even for the same search.
Example Ryan used: a user looking for a hiking sleeping mat. The LLM fans the query out into multiple sub-queries before searching:
- Characteristics: “most durable sleeping mat”
- Comparisons: “patagonia vs fjallraven”
- Date-specific: “best hiking backpack 2026”
- Common questions: “what r-value for roll mat”

The search index sees those sub-queries — not the original prompt. And because the LLM generates them probabilistically, the same prompt 1,000 times will produce different fan-outs.
Takeaway #3: don’t obsess over individual fan-out queries; look for common themes across many queries. The patterns — comparison adjacencies, date-stamped variants, recurring sub-questions — are the actionable signal.
Part 4: Citations
Even when your page is retrieved during grounding, it might still not appear in the final answer.
- 50% of retrieved URLs get thrown away before the final answer is generated (Ahrefs research)
- LLMs don’t “read” pages — they retrieve snippets (Dejan.ai). The snippet, expanded by a line or two for context, is the unit of evaluation
What predicts citation:
- Cited URLs have stronger semantic similarity: the correlation between fan-out query and cited URL title was 0.656. Your title is doing more work than you think
- Fresher sources are more likely to be cited: the average age of URLs cited by AI search engines is 1,064 days vs 1,432 days in organic SERPs — about 25.7% fresher (Ahrefs research)
- Listicles get cited like crazy: in Ahrefs’ study of 750 top-of-funnel prompts (e.g. “best web design agencies in London”), 43.8% of all source links were listicles (Ahrefs research)
- Longer isn’t always better: the average word count of pages cited in AI Overviews is 1,282 words (Ahrefs research). The full word count distribution of cited pages:
- Under 350 words: 16.6%
- 350–1,000 words: 36.8% (the largest bucket)
- 1,000–2,000 words: 30.6%
- Over 2,000 words: 16.0%
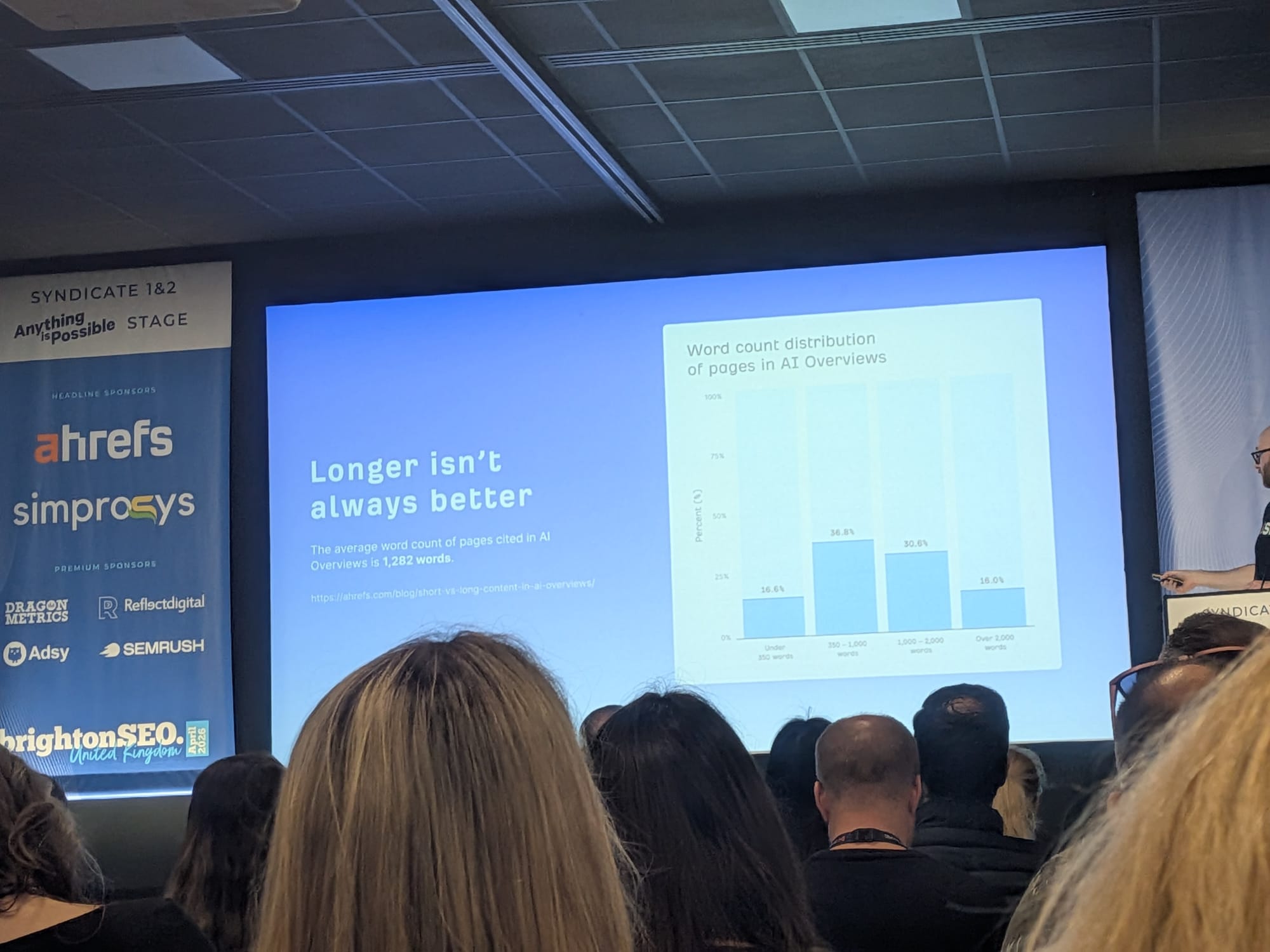
Ryan closed this part with a Dan Petrović quote: Adding more content dilutes your coverage percentage without increasing what gets selected… Density beats length. Focus on being the most relevant source for a query, not the longest.
Takeaway #4: make the relevance and value of your page easy to understand, even without reading the whole page.
How to Write for Snippet Retrieval
Ryan’s specific writing recommendations:
1. Don’t do “chunking” like this — breaking text into tiny fragmented paragraphs to “help” the LLM. The way you chunk doesn’t correspond to how an LLM chunks snippets; it just makes for worse reading.
2. Clear, specific writing is good for AI and humans.
3. BLUF (Bottom Line Up Front). When you have an important point, open with it.
- Before: “After analyzing our site’s backlink profile, reviewing keyword rankings across 200 target terms, and comparing our domain authority to three main competitors…”
- After: “Our organic traffic decline is caused by thin content on product pages. This became clear after analyzing our backlink profile, keyword rankings across 200 terms, and domain authority relative to three competitors.”
4. Declarative sentences. Hedged language reduces retrieval.
- Before: “It seems like it might be a good idea to maybe consider updating your title tags, since they could potentially help improve your click-through rates in search results.”
- After: “Update your title tags. They directly improve click-through rates in search results.”
5. Repeated takeaways. State critical points in intro, middle, and outro. Don’t assume the one mention will be the snippet retrieved.
6. High entity density. Be specific. Refer to named entities.
- Before: “There are a lot of things you can do to make your website show up better in search results…”
- After: “Optimizing meta titles, internal links, and Core Web Vitals improves your Google rankings and increases organic traffic.”
Part 5: Personalisation
AI search engines personalise results to individual users. Same prompt, different answers depending on the user’s history, memory, and the system prompt at the start of the conversation.
Ryan quoted Mark Williams-Cook again: If you were playing soccer, the “training data” is your long-term muscle memory. The system prompt is what your coach tells you just before you get on the field. The system prompt has disproportionate influence on final generation.
Takeaway #5: track average visibility over time and across many prompts. Don’t fixate on what your CEO sees in their personal ChatGPT. Their personalisation history is probably radically different from your customers’.
This is exactly what Ahrefs’ Brand Radar is designed to do — it tracks average visibility across 353 million prompts in ChatGPT, AI Mode, AI Overviews, Copilot, Gemini, and Grok. It also monitors brand mentions across the web, YouTube, TikTok, Reddit, and analyses/clusters query fan-outs at scale.
Personal Takeaways
This is my third BrightonSEO (Brighton 2025, San Diego 2025, Brighton 2026), and Ryan’s session sat with the strongest of the conference for me — alongside Tom Capper’s Day 1 pixel-position research and Philip Armstrong’s session that followed Ryan’s in the same track. All three shared a quality: genuinely new analytical frameworks backed by Ahrefs- or Semrush-grade empirical data, not repackaged industry talking points.
What I’m taking home:
- The 5-part stack is the most useful mental model for AI SEO I’ve encountered. Most “AI SEO” advice circulating online conflates these layers — telling you to “write for LLMs” without specifying whether the optimisation is for training, grounding retrieval, fan-out, citation selection, or personalisation. Ryan’s framework lets you ask: which part does this tactic actually affect?
- The 0.664 / 0.74 brand mention correlations are the headline numbers. They cleanly answer the question every client is asking: “What’s the highest-leverage thing we can do to show up in AI?” Answer: get mentioned everywhere relevant on the open web, with particular weight on YouTube. The classic “domain authority” signals (DR 0.326, backlinks 0.218) correlate too, but at less than half the strength. That maps directly to PR, digital PR, and creator-led content placement — disciplines most SEO teams underinvest in.
- The 12% statistic — only 12% of AI-cited links rank for the original prompt — is the most consequential single data point. It means traditional rank-tracking will continue to systematically miss AI visibility. We’ve been measuring the wrong query the whole time.
- The “1,064 vs 1,432 days” freshness finding is more nuanced than I’d been telling clients. AI-cited URLs are ~25.7% fresher than organic SERPs, but they’re not new content — the median is still about three years old. The right framing for clients isn’t “publish more” but “refresh strategically”.
- The word count distribution is the one that will be most uncomfortable for skyscraper-content shops. Two-thirds of AI-cited pages sit between 350 and 2,000 words. Pages over 2,000 words are only 16.0% — roughly the same share as pages under 350 words. Combined with Dan Petrović’s “density beats length” framing, this is going to reset a decade of “longer = better” orthodoxy. I’ll be reviewing my own client recommendations on content length with this in mind.
- The BLUF principle finally has data behind it. It’s no longer a stylistic preference — there’s measurable retrieval advantage. I’ll be reinforcing this with every writer I work with at A-Digital Works.
Across the BrightonSEOs I’ve attended, only a handful of sessions have actually moved my analytical model of how SEO works. Tom Capper on pixel position was one. Ryan’s 5-part AI search stack is another. They share a quality — both speakers brought original, large-N data and used it to update industry priors rather than reaffirm them.
Related Resources
- Official talk page: How AI Search Engines Really Work (BrightonSEO)
- Speaker profile: Ryan Law (BrightonSEO)
- Ryan Law on LinkedIn
- Ahrefs Brand Radar — the AI-visibility tracker referenced throughout the talk
- Ahrefs blog: AI Overview brand correlation (0.66 finding)
- Ahrefs blog: AI brand visibility correlations (YouTube 0.74 finding)
- Ahrefs blog: AI search overlap (12% finding)
- Ahrefs blog: Why ChatGPT cites pages (50% retrieved URLs thrown away, 0.656 title correlation)
- Ahrefs blog: Do AI assistants prefer fresh content (1,064 vs 1,432 days finding)
- Ahrefs blog: Best lists research (43.8% listicle finding)
- Ahrefs blog: Short vs long content in AI Overviews (1,282 words finding)
- Dejan.ai: How GPT sees the web (snippet retrieval)
About the Author
Ayaka Uchida (打田彩夏) — Founder & CEO of A-Digital Works Ltd. Founder of Nihon GO! World (Fitzrovia, London and Manchester). 10+ years in international business development across Japan, Singapore, US, and UK. BrightonSEO attendee 3 times (April 2025 Brighton, September 2025 San Diego, April 2026 Brighton — scholarship recipient). Aoyama Gakuin University, Faculty of Law. Fluent in Japanese and English; studying Spanish, French, and German.
Connect: a-digitalworks.com | LinkedIn
About A-Digital Works
A-Digital Works Ltd is a London-based Japan–UK SEO and EN↔JA localisation consultancy supporting UK, EU, and US companies entering the Japanese market. Services span keyword research in Japanese, content localisation, technical SEO, and market entry strategy. Flagship case study: Descartes Systems Group (Canadian logistics technology) — full Japanese-market SEO programme covering 物流システム, EDIシステム, and 配車システム.
This report covers Ryan Law’s session “How AI Search Engines Really Work” on the Anything is Possible stage of BrightonSEO Brighton on Friday 1 May 2026.