TL;DR
- AI検索には5つの構成パートがある: 学習、グラウンディング/RAG、クエリファンアウト、引用(Citations)、パーソナライズ。AI検索の最適化とは、各パートが何をするかを理解することであって、「SEOをより上手くやる」ことではない
- Ahrefsの約75,000ブランド調査でAI Overviewブランド言及と最も強く相関した要因はブランドのウェブ言及(0.664) — DR(0.326)やバックリンク(0.218)の相関の倍以上。YouTubeでの言及はさらに強く0.74
- AI引用リンクのうちユーザーの元プロンプトでランクしているのは約12%だけ — LLMはプロンプトを検索せず、複数のサブクエリに分解する(クエリファンアウト)から
- AIエンジンはページ全体ではなくスニペットを取得する。引用URLはファンアウトクエリと意味的類似度が強い(タイトル相関0.656)、AI引用URLの平均年齢は1,064日 vs オーガニックSERPの1,432日 — 約25.7%新しい
- Ahrefsが750のトップ・オブ・ファネル・プロンプトを分析、引用ソースリンクの43.8%がリスティクル。AI Overview引用ページの平均ワード数は1,282語 — 中間帯(350〜2,000語)が引用の約67%、2,000語超はわずか16.0%。密度が長さに勝る
- Brand Radar(AhrefsのAI可視性トラッカー)はChatGPT、AI Mode、AI Overviews、Copilot、Gemini、Grokをまたぐ3億5,300万プロンプトをインデックス化 — パーソナライズによって単発の「うちのブランド出てる?」チェックが信頼できないことから設計された
セッション情報
トーク題目: How AI Search Engines Really Work
トラック: Understanding AI Behaviour
日時: 2026年5月1日(金) 14:00
会場: Syndicate 1&2 — Anything is Possible stage, Brighton Centre, Kings Road, Brighton and Hove, BN1 2GR, United Kingdom
登壇者について
Ryan Law — Director of Content Marketing, Ahrefs
RyanはAhrefsのコンテンツマーケティングを統括し、SEO業界で最も引用される執筆者・アナリストの一人。以前はコンテンツマーケティングエージェンシーAnimalzのCMO、エージェンシー共同創業者。キャリアを通じてGoogle、GoDaddy、Zapierなどの企業と協業してきた。Day 2の「Understanding AI Behaviour」トラックでのRyanのセッションは、Veronika Ulla Höller(Tresorit)、Philip Armstrong(Semrush)と並び、カンファレンス全体で最もリサーチに裏付けられたセッションの1つだった。
セットアップ: 「ChatGPTやAI Modeが商品を推薦するとき、実際に何が起きているのか?」
Ryanは自分をステージに連れて来た質問を率直に認めて切り出した: コンテンツマーケターとして、ChatGPTで引用されたい。本気で。(*パニックの呼吸音*)。それには、これらのシステムの中で実際に何が起きているのかを理解する必要がある。だからリサーチとフレームワークを携えてBrightonSEOに来た。
検索の未来についての彼のフレーミング: フォローアップ質問ができる、パーソナライズされた応答、ゼロクリック回答、インタラクティビティとエージェンシー。すべてはそこに向かう。
AI検索の5つの構成パート
Ryanのワーキングモデル — トークの背骨:
- Training(学習) — あなたのブランドを「学習する」
- Grounding(グラウンディング) — 従来の検索インデックスを使う
- Query fan-out(クエリファンアウト) — 情報を見つけるための検索クエリを生成する
- Citations(引用) — どのURLを引用するか選ぶ
- Personalisation(パーソナライズ) — 個々のユーザーに合わせて回答を調整する
各パートには独自の最適化ロジックがある。オンラインに流通する「AI SEO」アドバイスのほとんどは、これらの層を混同している。Ryanのフレームワークはアドバイスを「この戦術は実際にどのパートに影響するのか?」でトリアージできる。

パート1: Training(学習)
LLMは巨大なコーパスで学習されている: Common Crawl、独自スクレイプ、ライセンスウェブデータ、Google Books、Project Gutenberg、BookCorpus、Wikipedia、GitHubリポジトリ、arXiv、PubMed/PMC、S2ORC、Reddit(Pushshift)、Stack Exchange、USPTO特許、FreeLaw、OpenSubtitles、Europarl。これらが中間データセット(C4、RefinedWeb、OSCAR、The Stack、WebText、The Pile、Dolma、ROOTS)を経て、オープンモデルとクローズドモデル両方の出力に流れ込む。すべてのモデルがCommon Crawlを使うわけではない — 独自スクレイプとライセンスデータがクローズドモデルを支える。
そのコーパス内でブランドがどう現れるかが、モデルがあなたについて「知っている」内容を形作る。RyanはGianluca Fiorelliを引用: 「LLMはあなたのブランドと『ジム』『ノイズキャンセリング』のような概念との関係を学習する。これらの意味的な関連付けが、あなたが言及されるかどうか、どう言及されるかに直接影響する」
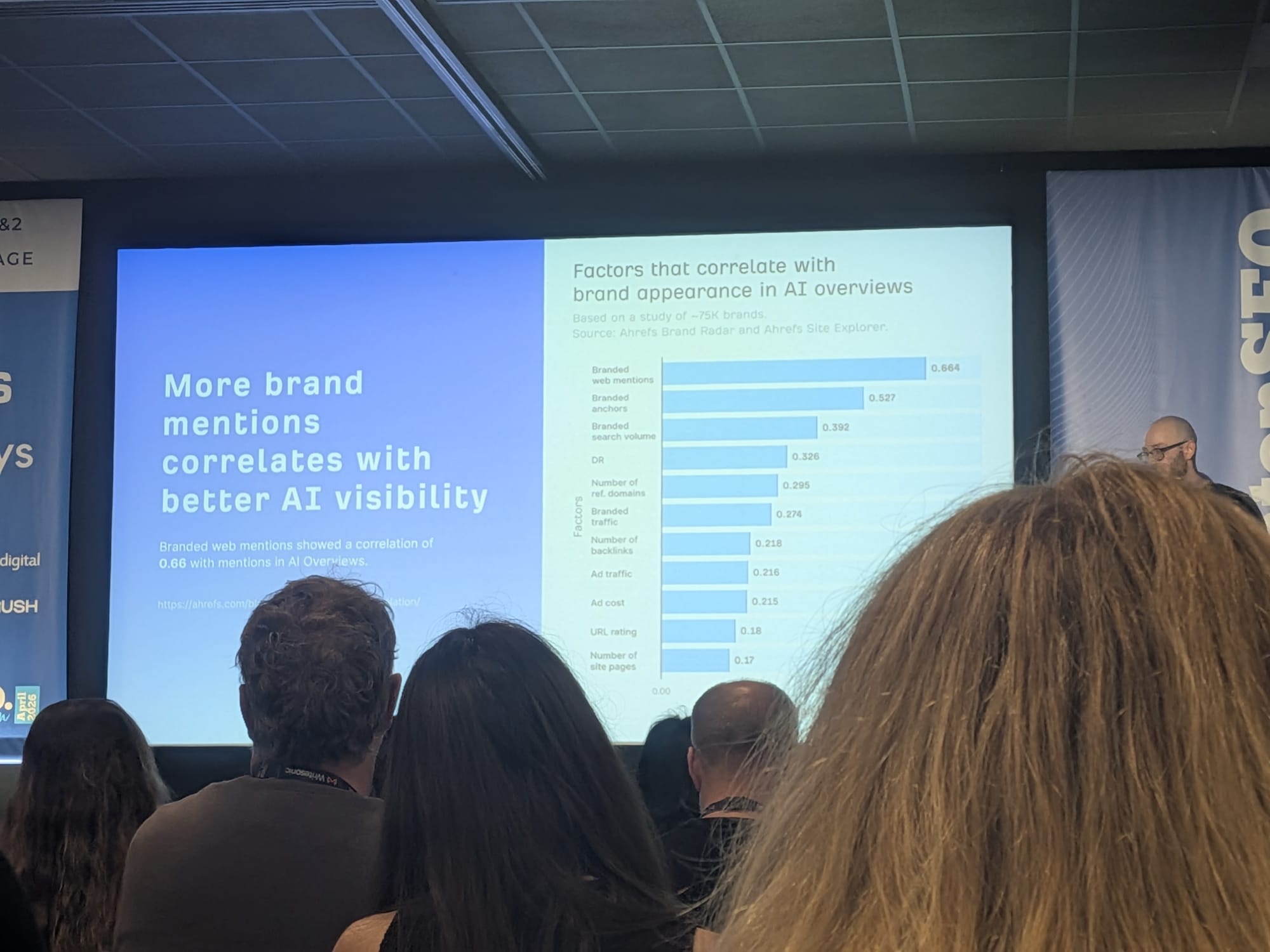
データ、相関係数の順 — Ahrefsの約75,000ブランドの研究から:
| 要因 | AI Overviewでのブランド出現との相関 |
|---|---|
| ブランドのウェブ言及 | 0.664 |
| ブランドアンカー | 0.527 |
| ブランド検索ボリューム | 0.392 |
| DR(ドメインレーティング) | 0.326 |
| 参照ドメイン数 | 0.295 |
| ブランドトラフィック | 0.274 |
| バックリンク数 | 0.218 |
| 広告トラフィック | 0.216 |
| 広告コスト | 0.215 |
| URLレーティング | 0.18 |
| サイトページ数 | 0.17 |
ブランドのウェブ言及がトップで0.664 — SEOリサーチの基準で言えば非常に大きな効果。注目すべきは、トップに無いもの: DR(0.326)、バックリンク数(0.218)、URLレーティング(0.18)。古典的な「ドメインオーソリティ」シグナルもAI Overview出現と相関するが、ドメイン外ブランド言及の半分以下の強さ。(出典: Ahrefsリサーチ。)
YouTubeでの言及はさらに強い相関、0.74を示した。開かれたウェブの中でブランドが言及されうるあらゆるサーフェスのうち、YouTubeはAI可視性に対して不釣り合いに大きな仕事をしている(Ahrefsリサーチ)。
Takeaway #1: 開かれたウェブの関連する多くの場所でブランドが言及されるようにする。地味だが、最もレバレッジの高い答え。
パート2: GroundingとRAG
LLMは素のままでは酷い検索エンジン。確率的で、ソースを帰属させず、ハルシネーションを起こしやすく、知識のカットオフがある。これを回避するため、AI検索エンジンはLLMをグラウンディングと検索拡張生成(RAG)で包む。
RyanはBritney Mullerの定義を引用: 「グラウンディングはground truth(地上検証)に由来し、統計学と元来は地図製作にルーツがある。文字通り『外に出て、自分の地図が現実と一致しているか確認する』という意味だった」。LLMが出力をグラウンドするとき、取得された現実世界の文脈に生成をアンカリングして、答えがハルシネーションで的外れにならないようにしている。
LLMがすべてのプロンプトで下す判断: 「この質問に答えるのに、もっと情報が必要か?」
グラウンディングを発動させる3つのシグナル:
- 学習範囲外 — 例「AhrefsのDRメトリクスはどう計算されているか?」
- 新しい情報が必要 — 例「Googleの直近のコアアップデートはいつ?」
- 帰属が要求される — 例「Googleがリランキングでクリックを使うことを確認するソースを提示せよ」
そして決定的に: AI検索エンジンは異なる検索インデックスを使う。ChatGPTはBing。PerplexityはBrave。GeminiはGoogle。AI OverviewsはGoogle。
Takeaway #2: 従来検索で上位ランクすることはAI検索の可視性を改善する。グラウンディングに使われる検索インデックスで上位にいるほど、グラウンディングステップで取得される確率が上がるから。「AI vs 従来型SEO」のフレームを殺す。両者は別の分野ではなく、スタック。
Ryanがここでフラグを立てたデータ: 引用リンクのうち元プロンプトでランクしているのは12%だけ(Ahrefsリサーチ)。LLMが引用するURLの大半は、ユーザーの実際のクエリでランクしているURLではない。これが次のパートにつながる…
パート3: Query Fan-Out(クエリファンアウト)

プロンプトは通常、検索クエリとしては悪い。だからLLMが分解する。
RyanはMark Williams-Cookを引用: 「ファンアウトクエリはLLM生成で非決定的: 同じ検索でも毎回変わり得る」
Ryanの具体例: 登山用スリーピングマットを探すユーザー。LLMは検索前に、プロンプトを複数のサブクエリにファンアウトする:
- 特性: 「最も耐久性のあるスリーピングマット」
- 比較: 「patagonia vs fjallraven」
- 日付指定: 「best hiking backpack 2026」
- よくある質問: 「what r-value for roll mat」

検索インデックスが見るのはこれらのサブクエリ — 元のプロンプトではない。そしてLLMが確率的に生成するため、同じプロンプトを1,000回送れば毎回違うファンアウトが出る。
Takeaway #3: 個々のファンアウトクエリに執着するな。多くのクエリをまたがる共通テーマを探せ。パターン — 比較の隣接関係、日付スタンプ付きバリアント、繰り返し出るサブ質問 — がアクショナブルなシグナル。
パート4: Citations(引用)
グラウンディング中にあなたのページが取得されたとしても、最終回答に現れるとは限らない。
- 取得されたURLの50%は最終回答生成前に捨てられる(Ahrefsリサーチ)
- LLMはページを「読まない」、スニペットを取得する(Dejan.ai)。スニペットを1-2行拡張したものが評価の単位
引用を予測する要因:
- 引用URLは意味的類似度が強い: ファンアウトクエリと引用URLタイトルの相関は0.656。タイトルは思っているより仕事をしている
- 新しいソースの方が引用されやすい: AI検索エンジン引用URLの平均年齢は1,064日 vs オーガニックSERPの1,432日 — 約25.7%新しい(Ahrefsリサーチ)
- リスティクルは爆裂に引用される: Ahrefsが750のトップ・オブ・ファネル・プロンプト(例「ロンドンの最高のウェブデザインエージェンシー」)を分析したところ、全ソースリンクの43.8%がリスティクルだった(Ahrefsリサーチ)
- 長ければ良いというものではない: AI Overviewで引用されるページの平均ワード数は1,282語(Ahrefsリサーチ)。引用ページのワード数分布の全体:
- 350語未満: 16.6%
- 350〜1,000語: 36.8%(最大バケット)
- 1,000〜2,000語: 30.6%
- 2,000語超: 16.0%
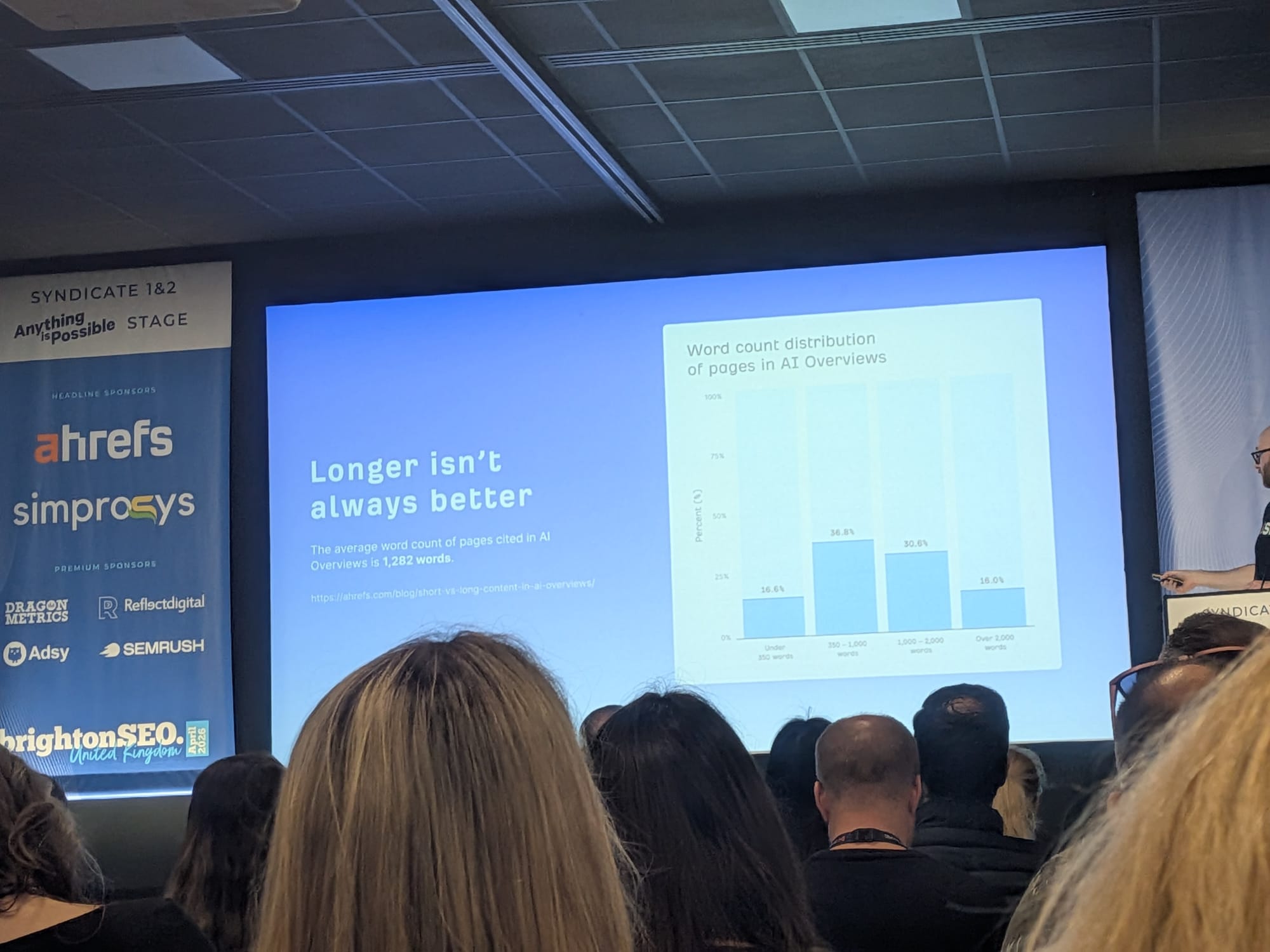
このパートをDan Petrovićの引用で締めた: 「コンテンツを追加すると、選ばれる量を増やさずにカバレッジ率が薄まる… 密度が長さに勝る。クエリにとって最も関連あるソースになることに焦点を当てよ、最も長いソースではなく」
Takeaway #4: ページの関連性と価値を、ページ全体を読まなくても理解できるようにせよ。
スニペット取得用の書き方
Ryanの具体的な執筆推奨:
1. このような「chunking」をするな — LLMを「助ける」ために細かい段落に断片化すること。あなたがチャンクする方法はLLMがスニペットをチャンクする方法と対応しない。ただ読みづらくなるだけ。
2. 明確で具体的な書き方は、AIにも人間にも良い。
3. BLUF(Bottom Line Up Front)。重要なポイントがあるなら、それで始める。
- Before: 「サイトのバックリンクプロファイルを分析し、200のターゲット用語にわたるキーワードランキングを確認し、ドメインオーソリティを主要競合3社と比較した結果…」
- After: 「オーガニックトラフィックの減少は、商品ページの薄いコンテンツが原因。これは、バックリンクプロファイル、200用語のキーワードランキング、競合3社に対するドメインオーソリティを分析した結果明らかになった」
4. 断定的な文。曖昧な言葉は取得率を下げる。
- Before: 「検索結果のクリックスルーレートを改善するのに役立つ可能性があるかもしれないので、タイトルタグを更新することを検討するのは良いアイデアかもしれません」
- After: 「タイトルタグを更新せよ。検索結果のクリックスルーレートを直接改善する」
5. テイクアウェイの繰り返し。重要なポイントはイントロ、本文、結論で繰り返す。1回の言及がそのまま取得されるスニペットになると仮定するな。
6. 高いエンティティ密度。具体的に。名前のあるエンティティを参照する。
- Before: 「ウェブサイトを検索結果でもっと表示させるためにできることはたくさんあります…」
- After: 「メタタイトル、内部リンク、Core Web Vitalsを最適化することで、Googleランキングが改善し、オーガニックトラフィックが増える」
パート5: Personalisation(パーソナライズ)
AI検索エンジンは個々のユーザーに結果をパーソナライズする。同じプロンプトでも、ユーザーの履歴、メモリ、会話冒頭のシステムプロンプトによって異なる答えが返る。
RyanはMark Williams-Cookを再度引用: 「サッカーをしているなら、『学習データ』は長期の筋肉記憶。システムプロンプトはコーチが試合直前にあなたに言うこと」。システムプロンプトは最終生成に対して不釣り合いに大きい影響を持つ。
Takeaway #5: 平均可視性を、時間をまたいで、多くのプロンプトをまたいで追跡せよ。あなたのCEOが自分のChatGPTで見るものに固執するな。彼らのパーソナライズ履歴は、顧客のものとは根本的に違う可能性が高い。
これがまさにAhrefsのBrand Radarが設計されている目的 — ChatGPT、AI Mode、AI Overviews、Copilot、Gemini、Grokをまたぐ3億5,300万プロンプトの平均可視性を追跡する。ウェブ、YouTube、TikTok、Redditでのブランド言及もモニタリング、ファンアウトクエリのスケール分析・クラスタリングも行う。
個人的な学び
BrightonSEO参加は今回で3回目(Brighton 2025、San Diego 2025、Brighton 2026)。Ryanのセッションは、Day 1のTom Capperのピクセルポジション研究、そしてRyan直後の同じトラックのPhilip Armstrongのセッションと並んで、カンファレンス全体で最強のセッションの1つ。3つすべてが共通する特性を持つ: 業界の常套句の再パッケージではなく、AhrefsやSemrushクラスの実証データに裏付けられた、本当に新しい分析フレームワーク。
持ち帰るもの:
- 5パートスタックは、私が出会った中で最も有用なAI SEOのメンタルモデル。オンラインに流通する「AI SEO」アドバイスのほとんどは、これらの層を混同している — 「LLM向けに書け」と言うが、最適化が学習、グラウンディング取得、ファンアウト、引用選択、パーソナライズのどれに対してなのか指定しない。Ryanのフレームワークは「この戦術は実際にどのパートに影響するのか?」でトリアージできる。
- 0.664 / 0.74のブランド言及相関がヘッドライン数字。クライアントが問うている問いに明快に答える: 「AIに表示されるために、最もレバレッジの高いアクションは?」 答え: 開かれたウェブの関連するあらゆる場所でブランドが言及されるようにする、特にYouTubeで。古典的な「ドメインオーソリティ」シグナル(DR 0.326、バックリンク0.218)も相関するが、半分以下の強さ。これはPR、デジタルPR、クリエイター主導コンテンツ配置の仕事に直接マップする — ほとんどのSEOチームが過少投資している分野。
- 12%統計 — AI引用リンクのうち元プロンプトでランクしているのは12%だけ — は最も影響の大きい単一データポイント。従来型ランクトラッキングは今後もAI可視性を体系的に見逃し続けることを意味する。我々はずっと間違ったクエリを測ってきた。
- 「1,064日 vs 1,432日」の鮮度発見は、クライアントに伝えてきたよりニュアンスが豊か。AI引用URLはオーガニックSERPより約25.7%新しいが、新規コンテンツではない — 中央値は依然約3年前。クライアントへの正しいフレーミングは「もっと公開せよ」ではなく「戦略的にリフレッシュせよ」。
- ワード数分布の発見は、スカイスクレイパー・コンテンツ・ショップにとって最も居心地が悪いはず。AI引用ページの3分の2が350〜2,000語の間。2,000語超はわずか16.0% — 350語未満のページとほぼ同じシェア。Dan Petrovićの「密度が長さに勝る」フレームと組み合わさると、これは「長い=良い」という10年の正統をリセットする。自社クライアントのコンテンツ長推奨を、これを念頭に見直す。
- BLUFの原則がついにデータの裏付けを得た。もはやスタイル上の好みではなく、測定可能な取得上の優位性がある。A-Digital Worksで一緒に仕事をするライター全員にこれを補強する。
私が参加してきたBrightonSEOで、SEOの動き方の分析モデルを実際に動かしたセッションは数件だけ。Tom Capperのピクセルポジションが1つ。Ryanの5パートAI検索スタックがもう1つ。両者は共通の特性を持つ — どちらの登壇者も、独自で大きなNのデータを持参し、業界の事前信念を再確認するのではなく更新するために使った。
関連リソース
- 公式トークページ: How AI Search Engines Really Work (BrightonSEO)
- 登壇者プロフィール: Ryan Law (BrightonSEO)
- Ryan Law(LinkedIn)
- Ahrefs Brand Radar — トーク全体で参照されたAI可視性トラッカー
- Ahrefsブログ: AI Overviewブランド相関(0.66発見)
- Ahrefsブログ: AIブランド可視性相関(YouTube 0.74発見)
- Ahrefsブログ: AIサーチオーバーラップ(12%発見)
- Ahrefsブログ: なぜChatGPTがページを引用するのか(50%取得URL廃棄、0.656タイトル相関)
- Ahrefsブログ: AIアシスタントは新鮮なコンテンツを好むか(1,064日 vs 1,432日発見)
- Ahrefsブログ: Best lists リサーチ(43.8%リスティクル発見)
- Ahrefsブログ: AI Overviewにおける短いコンテンツ vs 長いコンテンツ(1,282語発見)
- Dejan.ai: GPTはウェブをどう見るか(スニペット取得)
著者について
打田彩夏(うちだ あやか) — A-Digital Works Ltd 創業者兼CEO。Nihon GO! World(ロンドン Fitzrovia & マンチェスター)創業者。日本、シンガポール、米国、英国での国際ビジネス開発10年以上。BrightonSEO参加3回(2025年4月Brighton、2025年9月San Diego、2026年4月Brighton — 最後の1回は奨学金参加)。青山学院大学法学部卒。日本語・英語ともにビジネスレベル、スペイン語・フランス語・ドイツ語を学習中。
Connect: a-digitalworks.com | LinkedIn
A-Digital Worksについて
A-Digital Works Ltdは、ロンドンを拠点とする日英SEOおよびEN↔JAローカリゼーションコンサルティング会社。UK・EU・米国企業の日本市場参入を支援。サービスは、日本語キーワードリサーチ、コンテンツローカリゼーション、テクニカルSEO、市場参入戦略にわたる。主要案件: Descartes Systems Group(カナダ物流テック) — 物流システム、EDIシステム、配車システムを軸とした日本市場SEOプログラム全般。
本レポートは、2026年5月1日(金)BrightonSEO BrightonのAnything is Possible stageで行われたRyan Lawのセッション「How AI Search Engines Really Work」をカバーしています。