TL;DR
- ChatGPT Shopping uses Google as its grounding source. The opening session moderator’s joke after Malte finished — “ChatGPT shopping is just Google shopping in a fancy hat” — captured the central finding well
- Product attributes (comfort, durability, versatility for running shoes) appear in ChatGPT’s product evaluation tables and act as scoring dimensions. If your product page doesn’t make these statements, your product likely never makes the cut
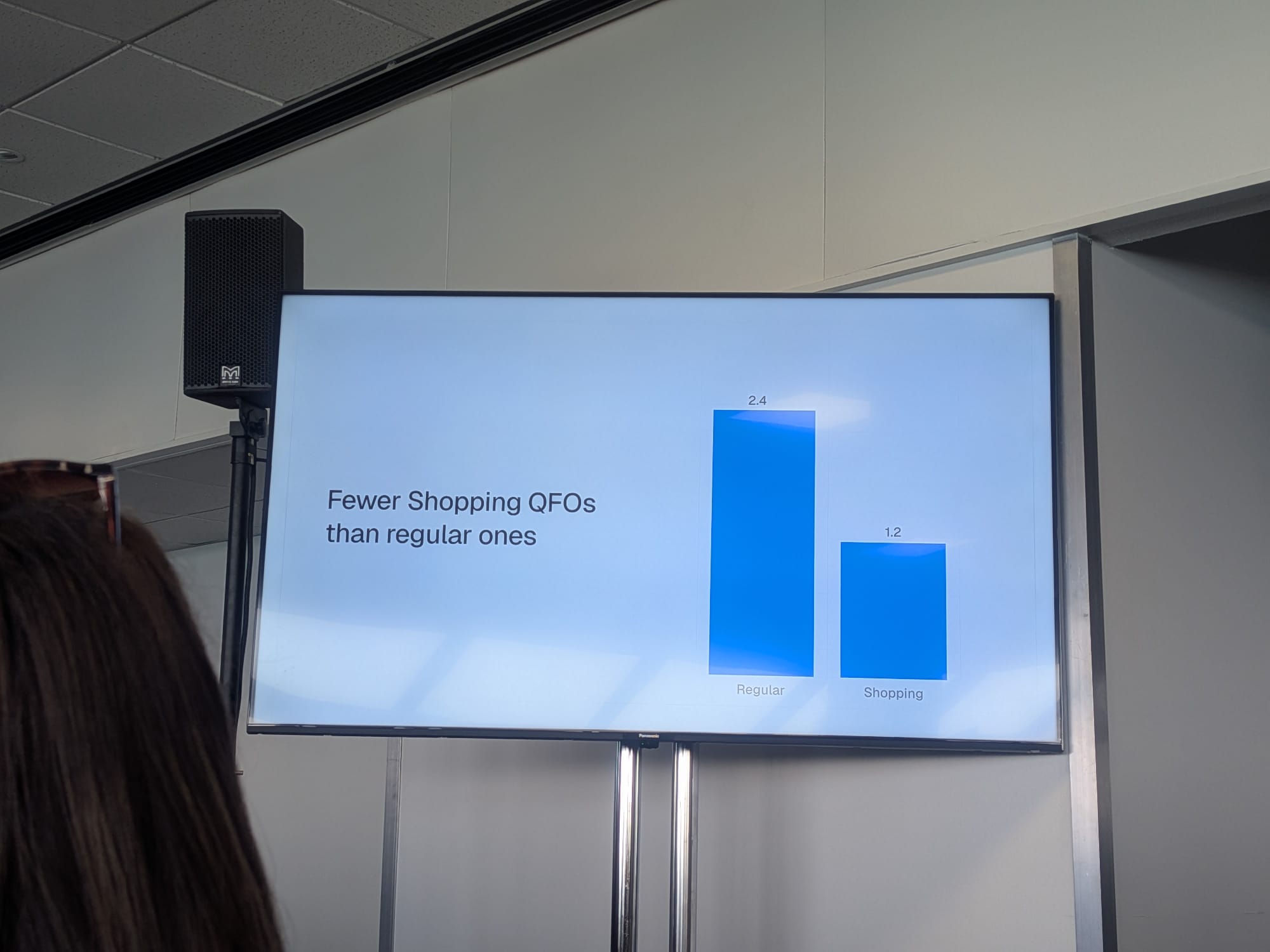
- Roughly 6% of ChatGPT shopping fan-out queries contain “2026”; ~1% contain “2025”. Year-tagged queries still help product visibility
- ~10% of ChatGPT shopping fan-out queries introduce the word “review.” ~20% of Grok’s do. Ranking for “[product name] review” and “[brand] review” is now a citation-relevant tactic, not just a reputation play
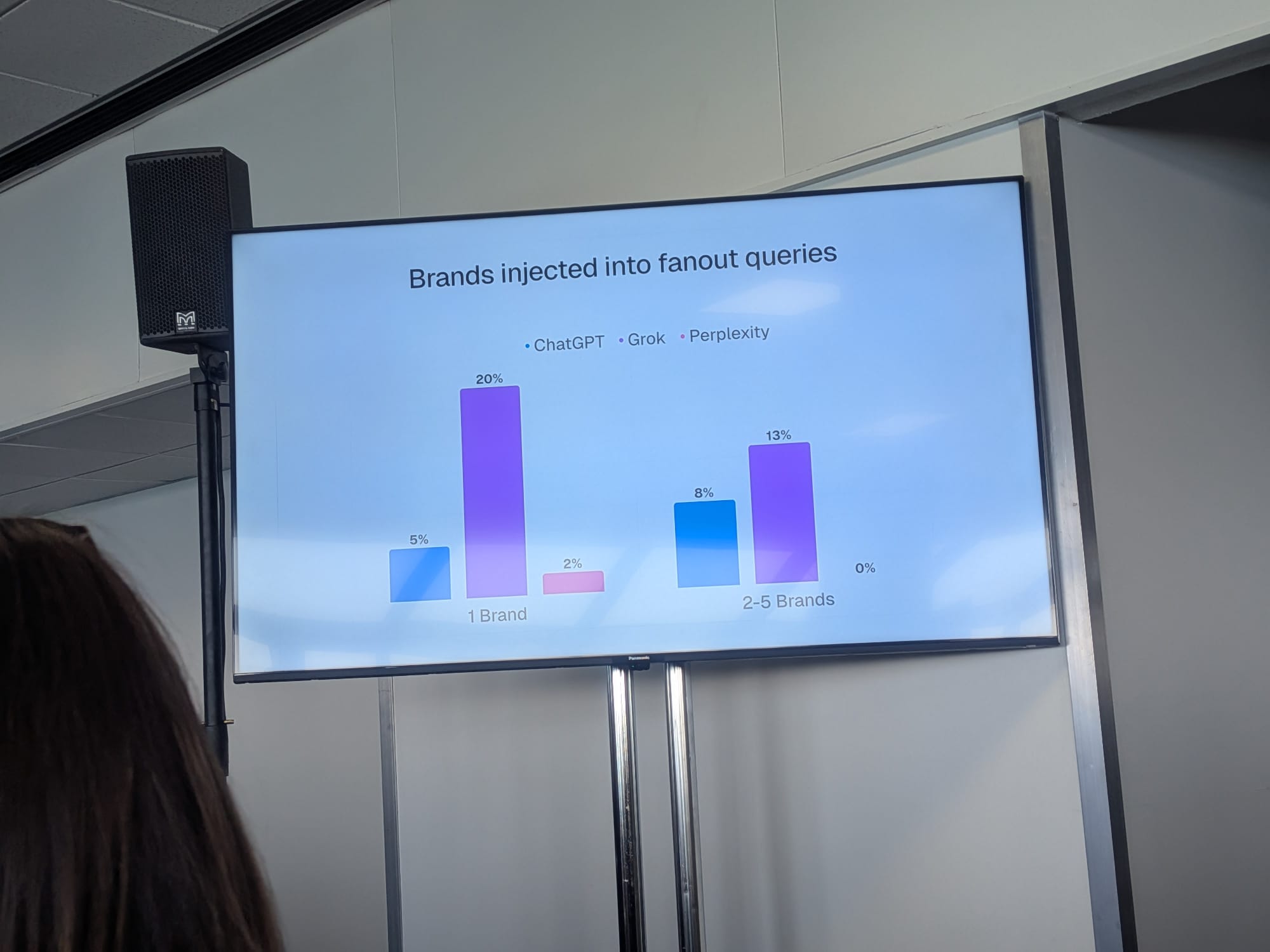
- 5% of ChatGPT fan-outs introduce a brand that wasn’t in the original prompt. Grok does it 20% of the time — sometimes adding 2–5 brands at once. Implication: AI shopping is performing brand discovery, not just retrieval, and the brands “added” by the LLM may be the ones with strongest external mention density
- Editorials (paid news placements) still influence LLM citations. Listicles still work. Self-promotional listicles still work — and roughly 9–10% of all listicles in Malte’s monitored data set are self-promotional, with the highest share coming from the professional services / SEO agency space

About the Session
Track: Retail
Date: Friday 1 May 2026, 09:30 AM
Venue: Skyline, Brighton Centre, Kings Road, Brighton and Hove, BN1 2GR, United Kingdom
About the Speaker
Malte Landwehr — CPO & CMO, Peec AI
Malte is one of the most respected technical SEO researchers in the German-speaking SEO community, with a decade-plus career spanning leadership roles at idealo International and Ladenzeile before co-founding Peec AI, the AI search visibility platform whose data underpins much of the research in this session. His Day 2 morning session opened the Skyline Stage with original empirical research on how ChatGPT performs product retrieval and grounding — analysing roughly 1 million product carousels and the underlying fan-out queries. The first half of the session covered Malte’s methodology — how the data set was built, how fan-out queries were extracted, and how he separated ChatGPT’s behaviour from other shopping AIs. This article focuses on the analytical findings from the second half.
The Core Finding: ChatGPT Shopping Runs on Google
The biggest takeaway from Malte’s analysis: when ChatGPT performs shopping queries, the grounding step routes through Google. ChatGPT’s product carousels — and the data that decides which products get into them — depend significantly on what Google can find.
This was the moderator’s “Scooby-Doo unmasking” moment at the end of the session: pull off the mask, and underneath ChatGPT shopping is Google shopping with extra steps.
Implication for SEOs: traditional Google product visibility (Merchant Center, structured product data, organic product page ranking) hasn’t been replaced by AI shopping — it’s now upstream of AI shopping. Optimising for Google shopping continues to feed AI shopping.
Product Attributes Drive AI Scoring
Malte’s running-shoe example anchored a concrete tactical finding.
When ChatGPT generates a product comparison table for a query like “best running shoes,” it scores products against attributes like comfort, durability, versatility. These attributes appear repeatedly across many queries.
The implication for product pages and product feeds:
- If you can repeatedly observe the same attributes appearing in fan-outs, those attributes are doing scoring work
- Products that score poorly on those attributes (low ratings on comfort, for example) tend to drop out of the carousel entirely
- Therefore: write self-contained, authoritative statements on your product pages that explicitly address those attributes
Malte’s recommended chunk format: roughly 50 words, two or three sentences, written with authoritative voice, ideally citing third-party validation.
His Nike example structure:
“The Pegasus has great comfort and is a very durable shoe, based on its 4.8 rating from runningmagazine.org and reviews on Runner’s World.”
The pattern: claim + attribute + external citation. Three sentences. Self-contained. Repeated for each attribute the LLM is scoring on.
For brands and manufacturers, he extended the recommendation: don’t just put these statements on your own product page. Push them into the content you share with retailers, marketplaces, and review sites. You want many statements across the web connecting your product to the attributes the LLMs are scoring.
Year-Tagged Queries Are Still Doing Work
Across Malte’s data set:
- ~6% of ChatGPT shopping fan-outs include “2026”
- ~1% include “2025”
- He found essentially zero queries containing 2023 or 2024
Pattern: LLMs lean on the current year to push toward fresh content. Including the current year in product titles, descriptions, and metadata still has measurable retrieval value — the practice didn’t disappear with AI search.

“Review” Is the Highest-Frequency Inserted Term
Malte compared fan-out behaviour across LLMs (using regular fan-outs since shopping fan-outs are only available for ChatGPT):
- ChatGPT: ~10% of fan-outs introduce the word “review” that wasn’t in the original prompt
- Grok: ~20% of fan-outs introduce “review”
If the LLM’s grounding step then runs “[product name] review” or “[brand] review” against Google or Bing, whoever ranks for those review queries influences the AI’s product judgement.
Tactical implication: this is now reputation management with citation consequences. Whether you rank yourself for “[your brand] review” or partner with publishers who do, that traffic is doing AI work, not just SEO work.
Why Grok Behaves So Differently
Malte spent some time on Grok specifically. Grok is unusually generous about exposing fan-out behaviour, which is why he uses it as a research data source.
His theory (uncertainty flagged): Grok appears to have implemented its fan-out logic by reading Google’s published research on the topic and copying the patterns. Whether that’s actually true or whether Grok arrived independently at the same patterns isn’t provable — but Grok is one of the cleanest windows into how a modern LLM might fan out queries, because it shows so much of its work.
By contrast: Perplexity is the laziest LLM in his data set. It rarely introduces new terms in fan-outs. It mostly just chunks up the user prompt and submits the chunks. Strategic implication: Perplexity grounding is closer to traditional keyword retrieval than ChatGPT or Grok grounding.
Brand Insertion in Fan-Outs
The most strategically interesting finding of the session. Before the data, an example of what fan-out behaviour actually looks like in practice — Malte’s hoodie prompt, which retains brand-related context even when the user doesn’t request it:


Across Malte’s data:
- ChatGPT: 5% of fan-out queries add 1 brand that wasn’t in the user’s original prompt; an additional 8% add 2–5 brands
- Grok: 20% of fan-out queries add 1 brand; an additional 13% add 2–5 brands
- Perplexity: 2% of fan-out queries add 1 brand; effectively 0% add multiple
When Grok adds brands, it sometimes adds two, three, four or five at once.
Two competing theories Malte presented for why this happens:
- Pre-search model knowledge. The LLM is using its training-data understanding of the category to suggest comparable brands before it even hits the web
- Sequential discovery. The first fan-out queries don’t include a brand, but content retrieved in the first round mentions brands, which then get added to the second-round fan-outs to look for specific reviews or comparisons
Malte was honest that he can’t prove which theory is correct. What’s certain: brands are being added to AI shopping queries that the user never typed.
The strategic implications:
- For merchants without brand loyalty (sells multiple brands): create rental/comparison pages that cluster category brands together — these get retrieved during the brand-insertion fan-outs
- For brands: the brands inserted by the LLM are likely the ones with the strongest external mention density. Reinforces Ryan Law’s 0.66 correlation finding from the same day’s afternoon track
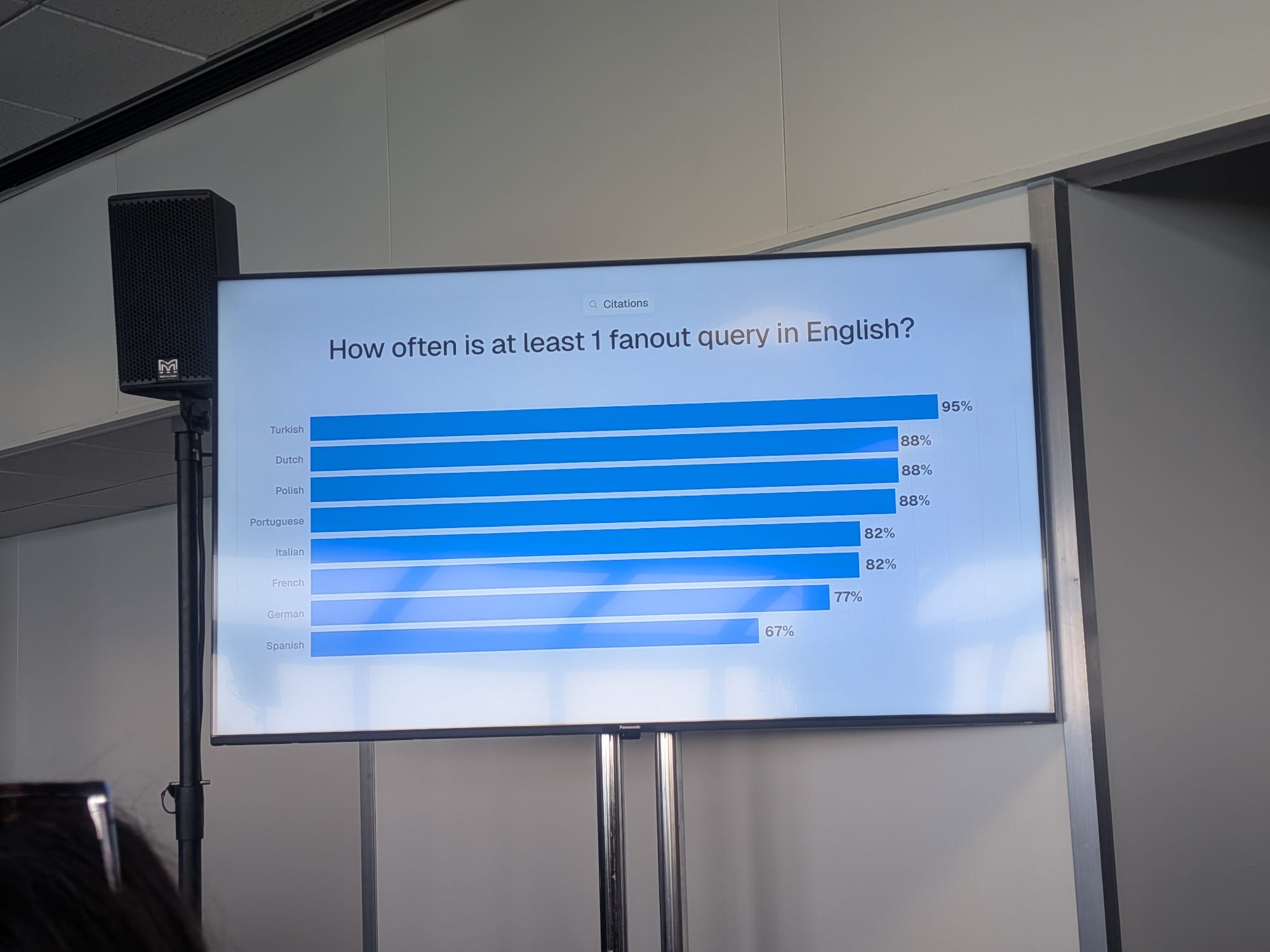
English-Language Grounding for Local Brands
Malte raised a finding that surprised the room. If you’re in a non-English-speaking market — say Poland — with a Polish IP, Polish prompt history, and a Polish prompt:
“There’s a high likelihood that one of the fan-out queries is in English.”
Meaning English-speaking documents will influence the grounding process even when the user speaks no English at all.
Tactical implication: local brands in non-English-speaking countries should have some of their content in English. Not the entire website (Malte was clear this isn’t the recommendation if your audience doesn’t care). But:
- Reviews on English-speaking review sites
- Interviews on English-speaking podcasts or industry portals
- English-language press releases
- Selected editorial placements in English
These don’t serve your end customer directly. They serve the AI grounding process that’s running in English alongside the user’s native-language conversation.
Editorials Still Work
This finding caused noticeable reaction in the room. Across Malte’s monitored data set in the insurance space, paid editorial placements in news publishers continue to act as LLM sources — and ChatGPT has done nothing about it since at least October 2025.
You can:
- Pay a news publisher to publish an article about your brand
- Have it labelled “this is an editorial” or even “advertorial”
- Have the disclosure say “this article is paid for by [Brand]”
…and ChatGPT will still cite it as a source for questions about that brand.
For SEOs working in countries where editorial placements are an active marketing channel — and Malte specifically mentioned the German market having a thriving paid-editorial publisher landscape — this is a meaningful tactical lever that hasn’t been blocked.
Listicles (Including Self-Promotional Ones) Still Work
The headline data: across Malte’s monitored prompts, listicles remain disproportionately influential as LLM citation sources, with format-prompt alignment becoming critical for visibility.

Two related findings:
Listicles work, even fabricated ones.
Claneo GmbH, a Berlin-based digital marketing agency, invented a fictitious matcha powder called “Matchatteus Premium” — the name a portmanteau of “Matcha” and Matthäus Michalik, one of Claneo’s co-founders — and wrote a few listicles about it. LLMs now sometimes recommend the non-existent matcha powder when asked about matcha — even citing it alongside real Japanese Uji-region brands.

You don’t need a brand website. You don’t need a real product. You need four or five well-placed listicles. Most of which, Malte suggested, are probably paid editorials anyway.
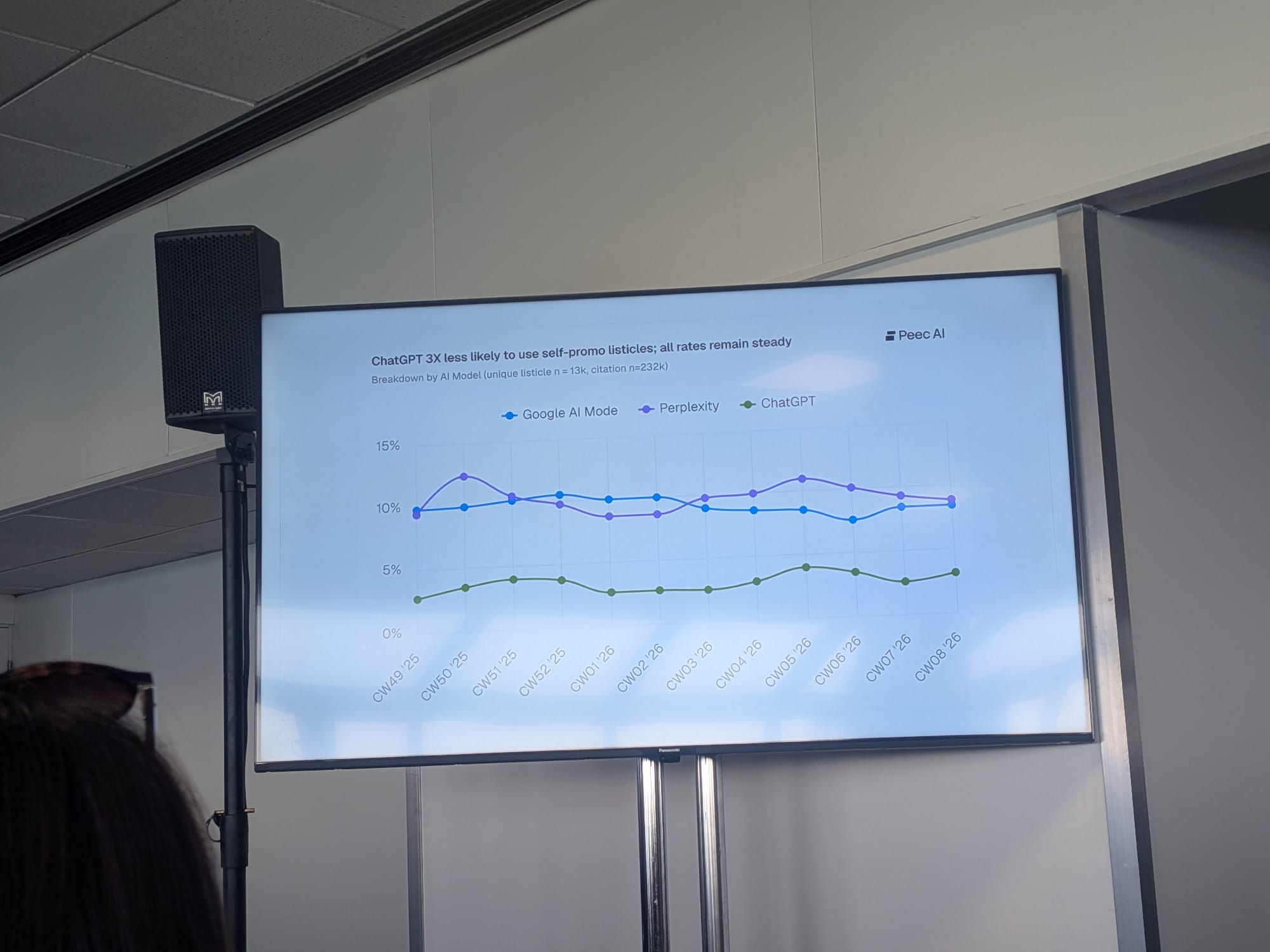
Self-promotional listicles work — moderately.
In Malte’s data set spanning roughly 1–2 million chats per day across multiple LLMs:
- Roughly 9–10% of all listicles cited as sources are self-promotional listicles — meaning the company writing the article also appears in their own list
- The highest share of self-promotional listicles comes from professional services, including SEO agencies (some readers will recognise themselves here)
- In e-commerce, the share is much lower — likely because almost nobody is doing it yet
- Effectiveness varies by LLM: weakest in ChatGPT, much stronger in Google AI Mode, Perplexity, and especially AI Overviews
Malte’s caveat: he’s not a big fan of AI Overviews and offered the data without enthusiasm.

Personal Takeaways
This is my third BrightonSEO (Brighton 2025, San Diego 2025, Brighton 2026), and Malte’s session was one of the strongest data-driven sessions of the entire conference for me — alongside Tom Capper’s pixel position research from Day 1 and Ryan Law’s five-mechanism stack from Day 2 afternoon. All three speakers shared the same essential quality: original, large-N empirical research that updates the industry’s working model rather than repackaging existing consensus.
What I’m taking home:
- The “ChatGPT shopping runs on Google” finding is the single most strategically clarifying insight of the day. The “AI vs traditional SEO” framing collapses entirely under this finding. They’re a stack: Google product visibility feeds AI product visibility. Optimising for one continues to feed the other.
- The product attribute scoring discipline is immediately copyable. For any e-commerce client, the workflow is now: monitor fan-outs for the product category, identify the recurring scoring attributes, write authoritative claim-attribute-citation statements on each product page covering those attributes. Most product pages are written for human shoppers and don’t make these structured claims explicitly. That’s an immediate optimisation gap.
- The brand-insertion-in-fan-outs finding directly connects to Ryan Law’s 0.66 correlation between off-domain brand mentions and AI Overview appearance. Two researchers, two different methodologies, same direction: brand mention density across the open web is the highest-leverage AI optimisation activity. Two confirmations of this thesis at one conference is more compelling than one.
- The English-grounding finding is the most practically useful one for my client base. A-Digital Works’ core service is helping non-Japanese brands enter Japan and Japanese brands enter the UK. Malte’s finding that English documents influence grounding even for non-English prompts means that some of our standard “translate the website into the local language and stop” recommendations are now incomplete. Selected English content — interviews, press, reviews — should remain alive and visible.
- Editorials and listicles still working is a clean, unsentimental insight — particularly for European markets where these are mature paid channels. It also means LLM signal hygiene is meaningfully behind Google’s: tactics that Google has actively penalised over the past five years still work in LLM grounding.
The Scooby-Doo unmasking joke at the end — “ChatGPT shopping is just Google shopping in a fancy hat” — was the second-best joke at the conference. (Sam Davis’s lying-in-sport opening still narrowly wins for me.)
Across the BrightonSEOs I’ve attended, the strongest sessions have always been the ones that introduced a genuinely new analytical contribution rather than refining existing industry consensus. Malte, Tom Capper, Ryan Law, and Philip Armstrong are the four speakers from BrightonSEO Brighton 2026 whose research I’d point clients at without hesitation.
Related Resources
- Session: How ChatGPT shops (BrightonSEO)
- Speaker profile: Malte Landwehr (BrightonSEO)
- Malte Landwehr on LinkedIn — most likely place to follow updates to this research
About the Author
Ayaka Uchida (打田彩夏) — Founder & CEO, A-Digital Works Ltd. Founder, Nihon GO! World (London Fitzrovia & Manchester). Over a decade of international business development across Japan, Singapore, the US, and the UK. Three-time BrightonSEO attendee (Brighton April 2025, San Diego September 2025, and Brighton April 2026 — the latter on scholarship). Aoyama Gakuin University Faculty of Law. Fluent in Japanese and English; studying Spanish, French, and German.
Connect: a-digitalworks.com | LinkedIn
About A-Digital Works
A-Digital Works Ltd is a London-based Japan–UK SEO and EN↔JA localisation consultancy supporting UK, EU, and US companies entering the Japanese market. Services span keyword research in Japanese, content localisation, technical SEO, and market entry strategy. Flagship case study: Descartes Systems Group (Canadian logistics technology) — full Japanese-market SEO programme covering 物流システム, EDIシステム, and 配車システム.
This report covers Malte Landwehr’s session “How ChatGPT shops: 1 million product carousels and the hidden fan outs that power them” at the Skyline Stage of BrightonSEO Brighton on Friday 1 May 2026.